
# Download utils from GitHub
!wget -q --show-progress https://raw.githubusercontent.com/CLDiego/uom_fse_dl_workshop/main/colab_utils.txt -O colab_utils.txt
!wget -q --show-progress -x -nH --cut-dirs=3 -i colab_utils.txtfrom pathlib import Path
import sys
repo_path = Path.cwd()
if str(repo_path) not in sys.path:
sys.path.append(str(repo_path))
import utils
from tqdm import tqdm
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
import pandas as pd
import torch
print("GPU available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("GPU device:", torch.cuda.get_device_name(0))
else:
print("No GPU available. Please ensure you've enabled GPU in Runtime > Change runtime type")
checker = utils.core.ExerciseChecker("SE03")
quizzer = utils.core.QuizManager("SE03")1. PyTorch workflow
The previous session we had a look at the basics of neural networks and how to train a single layer perceptron. In this session we will look at the PyTorch framework and how to use it to build and train neural networks.
Most deep learning projects follow a similar workflow. The following figure illustrates the typical workflow of a PyTorch project:
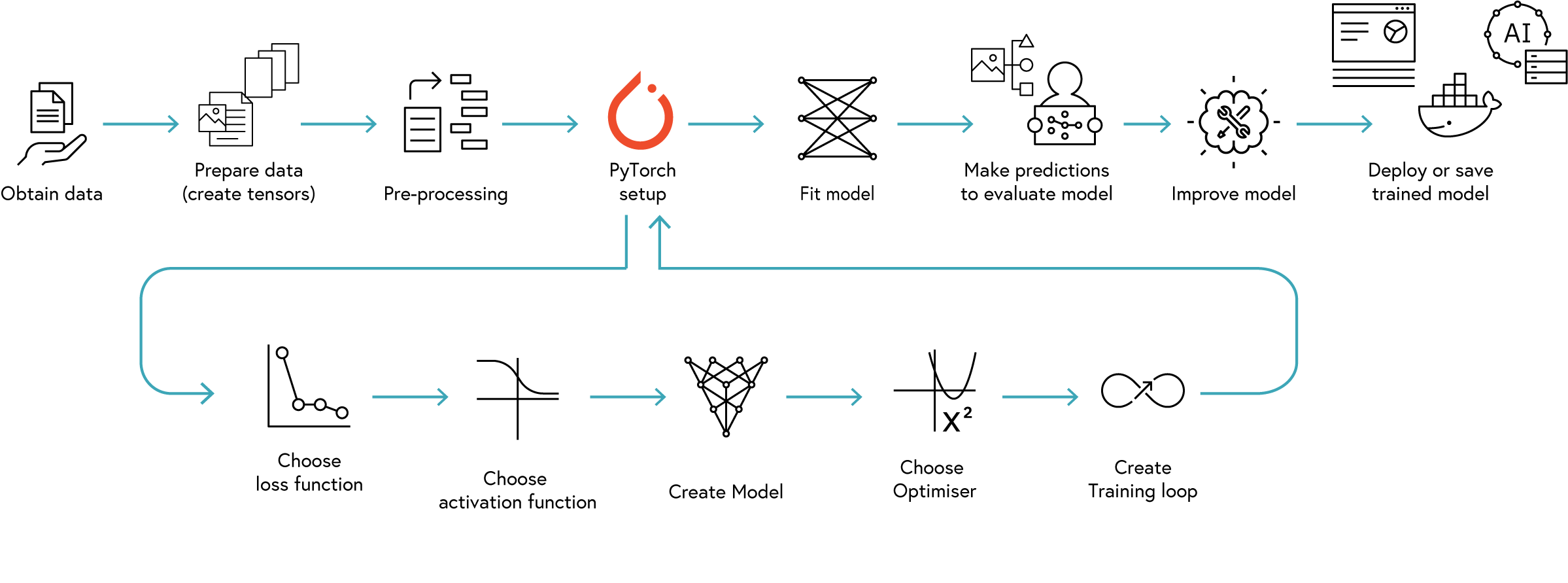
The workflow consists of the following steps:
| Step | Description |
|---|---|
| Obtain Data | Collect and preprocess the data for training and testing |
| Prepare Data | Setup data in PyTorch format |
| Pre-process Data | Normalize and augment the data. This may involve data cleaning, normalization, and splitting the data into training, validation, and test sets. |
| Activation Function | Choose an activation function for the model. This may involve selecting a suitable activation function for the model, such as ReLU, sigmoid, or tanh. |
| Model | Define the model architecture. |
| Choose optimiser | Select an optimiser for the model. |
| Choose loss function | Select a loss function for the model. |
| Create training loop | Define the training steps, including forward pass, backward pass, and parameter updates. |
| Fit model | Train the model using the training data. |
| Evaluate model | Evaluate the model using the validation and test data to make predictions |
| Improve model | Fine-tune the model by adjusting hyperparameters, adding regularization, or modifying the architecture. |
| Save or deploy model | Save the trained model for future use or deploy it in a production environment. |
Step 1: Obtain Data
In this notebook we are going to be using the ARKOMA dataset. The dataset is intended to be used as a benchmark for the creation of Neural Networks to perform inverse kinematics for robotic arms using a NAO robot. The dataset contains data for two different robotic arms: the left arm and the right arm. The data is generated using a physics engine that simulates the movement of the robotic arms in a 3D environment. The dataset contain 10,000 input-output data pairs for both arms. The input data is the end-effector position of the robotic arm, and the output data is the joint angles of the robotic arm.
The input parameters are:
| Notation | Description |
|---|---|
| $ P_{x} $ | The end-effector position with respect to the torso’s x-axis |
| $ P_{y} $ | The end-effector position with respect to the torso’s y-axis |
| $ P_{z} $ | The end-effector position with respect to the torso’s z-axis |
| $ R_{x} $ | The end-effector orientation relative to the torso’s x-axis |
| $ R_{y} $ | The end-effector orientation relative to the torso’s y-axis |
| $ R_{z} $ | The end-effector orientation relative to the torso’s z-axis |
The output parameters are:
| Notation | Left Arm Joint | Left Arm Range(rad) | Right Arm Joint | Right Arm Range(rad) |
|---|---|---|---|---|
| $ \theta_{1} $ | LShoulder Pitch | [-2.0857, 2.0857] | RShoulder Pitch | [-2.0857, 2.0857] |
| $ \theta_{2} $ | LShoulder Roll | [-0.3142, 1.3265] | RShoulder Roll | [-1.3265, 0.3142] |
| $ \theta_{3} $ | LElbow Yaw | [-2.0857, 2.0857] | RElbow Yaw | [-2.0857, 2.0857] |
| $ \theta_{4} $ | LElbow Roll | [-1.5446, 0.0349] | RElbow Roll | [-0.0349, 1.5446] |
| $ \theta_{5} $ | LWrist Yaw | [-1.8238, 1.8238] | RWrist Yaw | [-1.8238, 1.8238] |
In this notebook, we are going to focus on the right arm. The data is stored in CSV format. To load the data, we will use the pandas library.
data_path = Path(Path.cwd(), 'datasets')
dataset_path = utils.data.download_dataset('ARKOMA',
dest_path=data_path,
extract=True,
remove_compressed=True)# Set the path to the datasets (already provided above)
right_arm_path = dataset_path / 'Right Arm Dataset'
# Create file paths using a dictionary comprehension and format strings
file_parts = ['Train', 'Val', 'Test']
dataset_files = {
part: {
'features': right_arm_path / f'R{part}_x.csv',
'targets': right_arm_path / f'R{part}_y.csv'
} for part in file_parts
}
# Unpack into individual variables for compatibility with existing code
feats_train = dataset_files['Train']['features']
targets_train = dataset_files['Train']['targets']
feats_val = dataset_files['Val']['features']
targets_val = dataset_files['Val']['targets']
feats_test = dataset_files['Test']['features']
targets_test = dataset_files['Test']['targets']Step 2 and 3: Prepare and Pre-process Data
The next step is to pre-process the data. This involves normalizing the data and splitting it into training, validation, and test sets.
Training, Validation, and Test Sets
One of the crucial steps in machine learning is to split the data into training, validation, and test sets. Each of these sets serves a specific purpose in the model development process:
| Dataset | Purpose | Typical Split | Usage | Analogy |
|---|---|---|---|---|
| Training Set | Used to train the model by adjusting weights and biases through backpropagation | 60-80% | Every training iteration | Like studying materials to learn a subject |
| Validation Set | Used to tune hyperparameters and monitor model performance during training to prevent overfitting | 10-20% | During model development | Like practice exams to gauge learning progress |
| Test Set | Used only once for final model evaluation; never used for training or tuning | 10-20% | Once, after training | Like a final exam with new, unseen questions |
The ARKOMA dataset has already been split into these three sets for us, which simplifies our workflow.
Note: The test set is our generalisation benchmark. It is important to keep the test set separate from the training and validation sets to ensure that the model’s performance is evaluated on unseen data. This helps us understand how well the model will perform in real-world scenarios.
# Load the datasets
# Training set
X_train = pd.read_csv(feats_train)
y_train = pd.read_csv(targets_train)
# Test set
X_test = pd.read_csv(feats_test)
y_test = pd.read_csv(targets_test)
# Validation set
X_val = pd.read_csv(feats_val)
y_val = pd.read_csv(targets_val)
print(f"X_train shape: {X_train.shape} | y_train shape: {y_train.shape}")
print(f"X_test shape: {X_test.shape} | y_test shape: {y_test.shape}")
print(f"X_val shape: {X_val.shape} | y_val shape: {y_val.shape}")X_train.head()y_train.head()Normalisation
Normalisation is a crucial step in the pre-processing of data for machine learning models. It involves scaling the input features to a similar range, which helps improve the convergence speed and performance of the model. In this notebook, we will use Min-Max normalization to scale the input features to a range of [0, 1]. The formula for Min-Max normalization is as follows:
\[X_{norm} = \frac{X - X_{min}}{X_{max} - X_{min}}\]Where:
- $ X_{norm} $ is the normalized value.
- $ X$ is the original value.
- $ X_{min} $ is the minimum value of the feature.
- $ X_{max} $ is the maximum value of the feature.
The normalisation parameters will be computed from the training set and then applied to the validation and test sets. This helps to prevent data leakage and ensures that the model is evaluated on unseen data.
| Benefit | Description | Impact on Training |
|---|---|---|
| Faster Convergence | Normalized inputs lead to better-conditioned optimization | Reduces training time |
| Numerical Stability | Prevents extremely large or small values | Reduces risk of gradient explosions/vanishing |
| Feature Scaling | Makes all features contribute equally to the model | Prevents certain features from dominating |
| Better Generalization | Helps models transfer between different images | Improves performance on unseen data |
Snippet 1: Normalisation using Min-Max scaling
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
# Fit the scaler on the training data
scaler.fit(X_train)
# Transform the training
X_train_scaled = scaler.transform(X_train)
# Inverse transform the scaled data to get the original values
X_train_original = scaler.inverse_transform(X_train_scaled)
# Exercise 1: Data Loading and Preprocessing 🎯
# Create PyTorch tensors from the training, validation, and test data
X_train_tensor = torch.tensor(X_train.values, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32)
X_val_tensor = torch.tensor(X_val.values, dtype=torch.float32)
y_val_tensor = torch.tensor(y_val.values, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test.values, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32)
# Create MinMaxScalers for feature and target normalization
x_scaler = # Your code here
y_scaler = # Your code here
# Fit the scalers on training data
x_scaler = # Your code here
y_scaler = # Your code here
# Transform all datasets and put them into tensors
X_train_scaled = # Your code here
X_val_scaled = # Your code here
X_test_scaled = # Your code here
y_train_scaled = # Your code here
y_val_scaled = # Your code here
y_test_scaled = # Your code here
# Check the normalized data range
print(f"X_train normalized range: [{X_train_scaled.min().item():.4f}, {X_train_scaled.max().item():.4f}]")
print(f"y_train normalized range: [{y_train_scaled.min().item():.4f}, {y_train_scaled.max().item():.4f}]")
# ✅ Check your answer
answer = {
'X_train_tensor': X_train_tensor,
'y_train_tensor': y_train_tensor,
'X_train_scaled': X_train_scaled,
'y_train_scaled': y_train_scaled,
'scale_range_min': X_train_scaled.min().item(),
'scale_range_max': X_train_scaled.max().item(),
}
checker.check_exercise(1, answer)Step 4: Activation Function
The next step is to choose an activation function for the model. The activation function introduces non-linearity to the model, allowing it to learn complex relationships in the data. The following table lists some common activation functions used in neural networks, along with their characteristics and best use cases:
| Function | Formula | Range | PyTorch Implementation | Best Used For |
|---|---|---|---|---|
| ReLU | $\displaystyle f(x) = \max(0, x)$ | $\displaystyle [0, \infty)$ | torch.nn.ReLU() |
Hidden layers in most networks |
| Sigmoid | $\displaystyle f(x) = \frac{1}{1+e^{-x}}$ | $\displaystyle (0, 1)$ | torch.nn.Sigmoid() |
Binary classification, gates in LSTMs |
| Tanh | $\displaystyle f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$ | $\displaystyle (-1, 1)$ | torch.nn.Tanh() |
Hidden layers when output normalization is needed |
| Leaky ReLU | $\displaystyle f(x) = \max(\alpha x, x)$ | $\displaystyle (-\infty, \infty)$ | torch.nn.LeakyReLU(negative_slope=0.01) |
Preventing “dead neurons” problem |
| Softmax | $\displaystyle f(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}}$ | $\displaystyle (0, 1)$ | torch.nn.Softmax(dim=1) |
Multi-class classification output layer |
The choice of activation function depends on the specific problem and the architecture of the neural network.
- ReLU is the most commonly used activation function in hidden layers of deep networks due to its simplicity and effectiveness.
- The activation function for the output layer depends on the type of problem being solved (e.g., regression, binary classification, multi-class classification). *
**Common Mistakes to Avoid:
- Mixing activation functions in the same layer (e.g., using ReLU and sigmoid together) can lead to unexpected behavior.
- Using activation functions that saturate (like sigmoid) in hidden layers can lead to vanishing gradients, making training difficult.
- Forgetting to apply the activation function to the output layer can lead to incorrect predictions (e.g., not using softmax for multi-class classification).
- Not considering the range of the output when choosing the activation function (e.g., using sigmoid for regression tasks).
print("\n🧠 Quiz 1: Choosing the right activation function")
quizzer.run_quiz(1)
print("\n🧠 Quiz 2: Combining activation functions")
quizzer.run_quiz(2)Step 5: Model
The next step is to define the model architecture. In order to create a Neural Network we need to stack multiple neurons together. This is known as a layer. A layer is a collection of neurons that work together to process the input data. A simple ANN is formed by three types of layers:
- Input Layer: Receives the input data.
- Hidden Layers: Intermediate layers that process the data.
- Output Layer: Produces the final output.
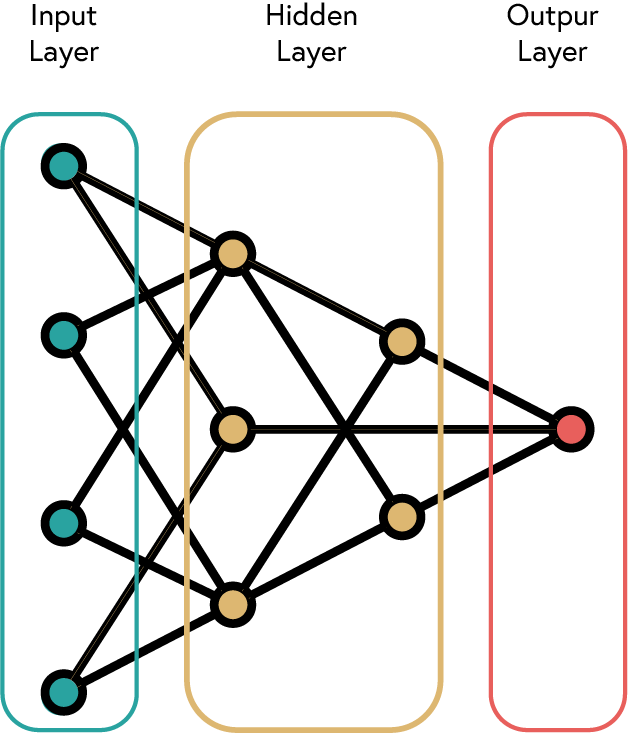
The following table summarises the different types of layers available in PyTorch:
| Layer Type | Class | Description | Common Uses |
|---|---|---|---|
| Fully Connected | torch.nn.Linear(in_features, out_features) |
Standard dense layer | Classification, regression |
| Convolutional | torch.nn.Conv2d(in_channels, out_channels, kernel_size) |
Spatial feature extraction | Image processing |
| Recurrent | torch.nn.RNN(input_size, hidden_size) |
Sequential data processing | Time series, text |
| LSTM | torch.nn.LSTM(input_size, hidden_size) |
Long-term dependencies | Complex sequences |
| Embedding | torch.nn.Embedding(num_embeddings, embedding_dim) |
Word vector representations | NLP tasks |
| BatchNorm | torch.nn.BatchNorm2d(num_features) |
Normalizes layer inputs | Training stability |
| Dropout | torch.nn.Dropout(p=0.5) |
Randomly zeros elements | Regularization |
The choice of layer type depends on the specific problem and the architecture of the neural network. For example, convolutional layers are commonly used in image processing tasks, while recurrent layers are used for sequential data processing.
Number of Layers and Neurons
The number of layers and neurons in each layer is a hyperparameter that needs to be tuned. The following table summarises the common practices for choosing the number of layers and neurons:
| Layer Type | Common Practices |
|---|---|
| Input Layer | Number of neurons = number of input features |
| Hidden Layers | 1-3 hidden layers are common for most tasks. More complex tasks may require more layers. |
| Output Layer | Number of neurons = number of output features (e.g., 1 for regression, number of classes for classification) |
| Number of Neurons | Common practices: 2^n, where n is the number of layers. A common practice is to start with a number of neurons equal to the number of input features and then reduce the number of neurons in each subsequent layer. |
- Start with a simple architecture and gradually increase complexity as needed.
- The number of neurons in each layer can be adjusted based on the complexity of the problem.
- Use activation functions after each layer to introduce non-linearity.
- Experiment with different layer types and configurations to find the best architecture for your problem.
# Quiz 3: Network Width
print("\n🧠 Quiz 3: Understanding Network Width for Inverse Kinematics")
quizzer.run_quiz(3)
# Quiz 4: Network Depth
print("\n🧠 Quiz 4: Understanding Network Depth for Inverse Kinematics")
quizzer.run_quiz(4)
# Quiz 5: Regularization Techniques
print("\n🧠 Quiz 5: Regularization Techniques for Kinematics Models")
quizzer.run_quiz(5)Initialising Weights and Biases
In the previous session we looked at the concept of weights and biases. With our Perceptron we initialised the weights and biases to random values. In PyTorch, we can use different methods to initialise the weights and biases of a neural network.
The importance of initialising weights and biases lies in the fact that they can significantly affect the convergence speed and performance of the neural network. Proper initialisation can help prevent issues such as vanishing or exploding gradients, which can hinder the training process.
| Initialisation Method | Formula | PyTorch Code | Description |
|---|---|---|---|
| Xavier/Glorot Initialisation | $\displaystyle W \sim \mathcal{U}(-\sqrt{\frac{6}{n_{in} + n_{out}}}, \sqrt{\frac{6}{n_{in} + n_{out}}})$ | torch.nn.init.xavier_uniform_(tensor) |
Suitable for sigmoid and tanh activations. |
| He Initialisation | $\displaystyle W \sim \mathcal{U}(-\sqrt{\frac{6}{n_{in}}}, \sqrt{\frac{6}{n_{in}}})$ | torch.nn.init.kaiming_uniform_(tensor) |
Suitable for ReLU activations. |
| Kaiming Normal Initialisation | $\displaystyle W \sim \mathcal{N}(0, \sqrt{\frac{2}{n_{in}}})$ | torch.nn.init.kaiming_normal_(tensor) |
Suitable for ReLU activations. |
| Kaiming Uniform Initialisation | $\displaystyle W \sim \mathcal{U}(-\sqrt{\frac{6}{n_{in}}}, \sqrt{\frac{6}{n_{in}}})$ | torch.nn.init.kaiming_uniform_(tensor) |
Suitable for ReLU activations. |
| Zero Initialisation | $\displaystyle W = 0$ | torch.nn.init.zeros_(tensor) |
All weights are set to zero. Not recommended. |
| Random Initialisation | $\displaystyle W \sim \mathcal{U}(-1, 1)$ | torch.nn.init.uniform_(tensor) |
Weights are randomly initialised between -1 and 1. |
- Use Xavier or He initialisation for most cases, as they are designed to maintain the variance of activations across layers.
- Avoid zero initialisation, as it can lead to symmetry problems where all neurons learn the same features.
- PyTorch uses Kaiming initialisation by default for
torch.nn.Linearlayers, which is suitable for ReLU activations.- Experiment with different initialisation methods to see their impact on training speed and model performance.
# Exercise 2: Model Creation with Weight Initialization 🎯
# In this exercise, you will:
# 1. Create a simple neural network model using PyTorch
# 2. Initialize weights and biases properly
# 3. Define layers with appropriate activation functions
# 4. Implement a forward method
class RobotArmNetwork(torch.nn.Module):
def __init__(self, input_size: int, hidden_size: int, output_size: int):
"""Initialize a neural network for robotic arm inverse kinematics
Args:
input_size: Number of input features
hidden_size: Number of neurons in the hidden layer
output_size: Number of output features
"""
# Initialize the parent class
# Your code here
# Define the layers of your neural network (simple architecture to avoid overfitting)
self.fc1 = # Your code here
self.hidden_activation = # Your code here
self.fc2 = # Your code here
# Initialize the weights using appropriate initialization techniques
# He/Kaiming initialization for layers with ReLU activation
# Your code here
# Your code here
# Xavier/Glorot initialization for the output layer
# Your code here
# Your code here
def forward(self, x):
"""Forward pass through the network"""
# Process input through first fully connected layer and activation function
x = # Your code here
# Process through output layer (no activation - we want raw values for regression)
x = # Your code here
return x
# Initialize your model with appropriate dimensions
model = # Your code here
# Print your model architecture
print(model)
# Print weight statistics to verify initialization
print("\nWeight initialization validation:")
print(f"First layer weight stats: mean={model.fc1.weight.mean().item():.4f}, std={model.fc1.weight.std().item():.4f}")
print(f"First layer bias: mean={model.fc1.bias.mean().item():.4f}, std={model.fc1.bias.std().item():.4f}")
print(f"Output layer weight stats: mean={model.fc2.weight.mean().item():.4f}, std={model.fc2.weight.std().item():.4f}")
print(f"Output layer bias: mean={model.fc2.bias.mean().item():.4f}, std={model.fc2.bias.std().item():.4f}")
# ✅ Check your answer
answer = {
'model': model,
'input_layer_size': model.fc1.in_features,
'output_layer_size': model.fc2.out_features,
'activation_type': model.hidden_activation.__class__,
'fc1_weight_stats': {
'mean': model.fc1.weight.mean().item(),
'std': model.fc1.weight.std().item()
},
'fc2_weight_stats': {
'mean': model.fc2.weight.mean().item(),
'std': model.fc2.weight.std().item()
},
'fc1_bias_stats': {
'mean': model.fc1.bias.mean().item(),
'std': model.fc1.bias.std().item()
},
'fc2_bias_stats': {
'mean': model.fc2.bias.mean().item(),
'std': model.fc2.bias.std().item()
}
}
checker.check_exercise(2, answer)Step 6: Choose Optimiser
Definition: Optimisers are algorithms used to update the model parameters during training to minimise the loss function.
The next step is to choose an optimiser for the model.
The optimiser algorithm is used to update the model parameters during training. Most optimizers use a version of gradient descent to update the model parameters. The goal of the optimiser is to minimize the loss function by adjusting the weights and biases of the model. The most commonly used optimizers include:
| Optimizer | PyTorch Implementation | Best Used For |
|---|---|---|
| Stochastic Gradient Descent (SGD) | torch.optim.SGD(params, lr) |
Simple problems, good with momentum |
| Adam | torch.optim.Adam(params, lr) |
Most deep learning tasks |
| RMSProp | torch.optim.RMSprop(params, lr) |
Deep neural networks |
| Adagrad | torch.optim.Adagrad(params, lr) |
Sparse data tasks |
| AdamW | torch.optim.AdamW(params, lr) |
When regularization is important |
The Adam optimiser is a popular choice for training deep learning models due to its efficiency and effectiveness. It combines the benefits of both SGD and RMSProp, making it suitable for a wide range of tasks.
Learning Rate
The learning rate is a hyperparameter that determines the step size at each iteration while moving toward a minimum of the loss function. A small learning rate may lead to slow convergence, while a large learning rate may cause the model to diverge. It is important to choose an appropriate learning rate for the optimizer to work effectively
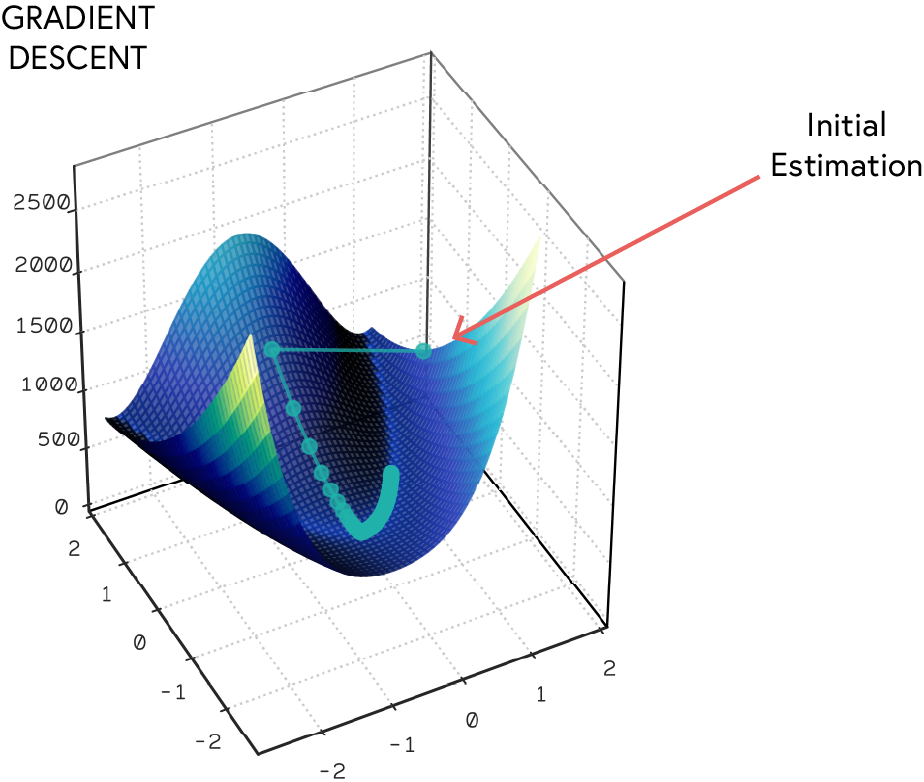
Step 7: Choose Loss Function
The next step is to choose a loss function for the model. The choice of loss function depends on the type of problem being solved. The loss function measures how well the model is performing and guides the optimisation process. The most commonly used loss functions include:
| Loss Function | PyTorch Implementation | Best Used For |
|---|---|---|
| Mean Squared Error (MSE) | torch.nn.MSELoss() |
Regression tasks |
| Mean Absolute Error (MAE) | torch.nn.L1Loss() |
Regression tasks |
| Binary Cross-Entropy | torch.nn.BCELoss() |
Binary classification tasks |
| Categorical Cross-Entropy | torch.nn.CrossEntropyLoss() |
Multi-class classification tasks |
| Hinge Loss | torch.nn.HingeEmbeddingLoss() |
Support Vector Machines (SVM) |
| Kullback-Leibler Divergence | torch.nn.KLDivLoss() |
Probabilistic models |
The loss works in conjunction with the optimiser. While there are loss functions that can work for the same task, the choice of loss will have an effect on the final performance of the model. For instance, using MSE (L2-Norm) loss for a regression task will penalise larger errors more than smaller ones, while MAE (L1-Norm) loss treats all errors equally. This can lead to different model performance depending on the distribution of the data.
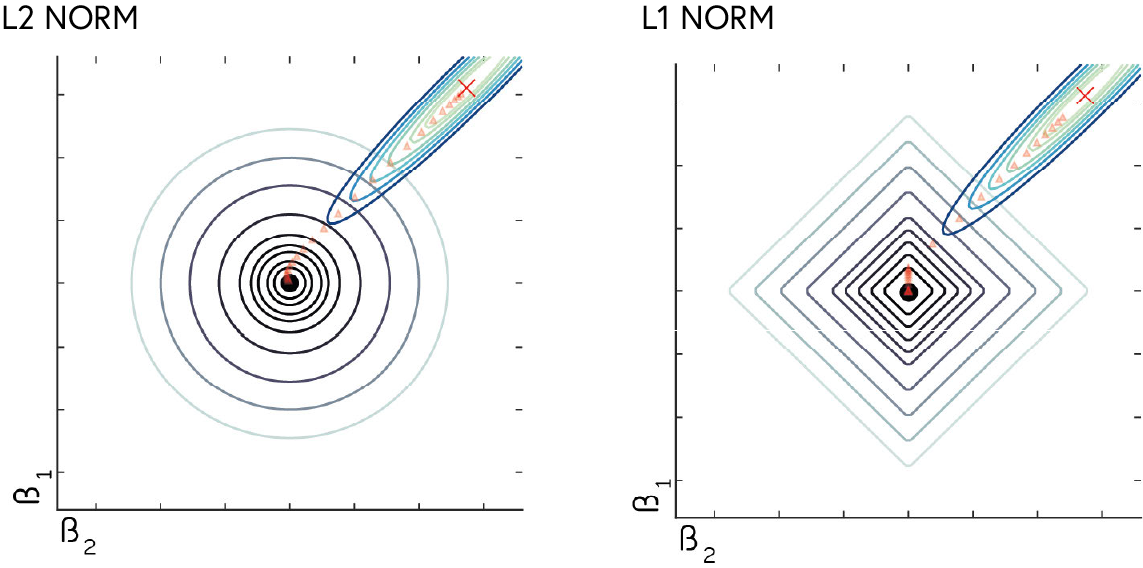
- Choose a loss function that is appropriate for the type of problem being solved (e.g., regression, classification).
- Monitor the loss during training to ensure that the model is converging and not overfitting.
- Experiment with different loss functions to see their impact on model performance.
# Exercise 3: Optimizer and Loss Function Selection 🎯
# In this exercise, you will:
# 1. Select an appropriate optimizer for your model
# 2. Choose a suitable loss function
# 3. Set the learning rate
# Create an Adam optimizer for your model
optimizer = # Your code here
# Create a Mean Squared Error loss function
loss_function = # Your code here
# Store the optimizer and loss function in the model for easy access
model.optimizer = optimizer
model.loss_function = loss_function
# Print the optimizer and loss function configuration
print(f"Optimizer: {type(model.optimizer).__name__}")
print(f"Learning rate: {model.optimizer.param_groups[0]['lr']}")
print(f"Loss function: {type(model.loss_function).__name__}")
# ✅ Check your answer
answer = {
'optimizer_type': type(optimizer),
'learning_rate': optimizer.param_groups[0]['lr'],
'loss_function_type': type(loss_function)
}
checker.check_exercise(3, answer)Step 8 and 9: Create Training Loop and Fit Model
The training loop implements the key steps for training a neural network model:
| Step | Description | Code Example |
|---|---|---|
| 1. Forward Pass | Pass input data through model to generate predictions | predictions = model(inputs) |
| 2. Loss Computation | Calculate loss between predictions and targets | loss = criterion(predictions, targets) |
| 3. Backward Pass | Compute gradients through backpropagation | loss.backward() |
| 4. Parameter Updates | Update model parameters using optimizer | optimizer.step() |
| 5. Gradient Reset | Zero out gradients for next iteration | optimizer.zero_grad() |
The next step is to fit the model using the training data. The model is trained for a specified number of epochs, and the training and validation loss is monitored during training. The number of epochs is a hyperparameter that determines how many times the model will be trained on the entire training dataset.
```python for epoch in range(num_epochs): # Set model to training mode model.train()
# 1. Forward Pass
predictions = model(inputs)
# 2. Loss Computation
loss = criterion(predictions, targets)
# 3. Backward Pass
loss.backward()
# 4. Parameter Updates
optimizer.step()
# 5. Gradient Reset
optimizer.zero_grad()
# Exercise 4: Creating a Training Loop 🎯
# In this exercise, you will:
# 1. Create a training loop for your neural network
# 2. Implement forward and backward passes
# 3. Monitor training and validation loss
def train_model(model,
train_features,
train_targets,
val_features,
val_targets,
epochs=100):
"""
Train a neural network model
Args:
model: PyTorch model to train
train_features: Training features
train_targets: Training targets
val_features: Validation features
val_targets: Validation targets
epochs: Number of training epochs
Returns:
train_losses: List of training losses
val_losses: List of validation losses
"""
# Initialize lists to store losses
train_losses = []
val_losses = []
# Put model in training mode
# Your code here
# Training loop
for epoch in tqdm(range(epochs), desc="Training"):
# 1. Zero gradients
# Your code here
# 2. Forward pass
predictions = # Your code here
# 3. Compute loss
loss = # Your code here
# 4. Backward pass
# Your code here
# 5. Update weights
# Your code here
# 6. Store training loss
train_losses.append(loss.item())
# 7. Compute validation loss
model.eval() # Set model to evaluation mode
with torch.no_grad(): # No need to track gradients for validation
val_predictions = model(val_features)
val_loss = model.loss_function(val_predictions, val_targets).item()
val_losses.append(val_loss)
# Set model back to training mode
model.train()
return train_losses, val_losses
# Run training for 100 epochs
train_losses, val_losses = train_model(
model=model,
train_features=X_train_scaled,
train_targets=y_train_scaled,
val_features=X_val_scaled,
val_targets=y_val_scaled,
epochs=300
)
# Plot training and validation loss
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(train_losses, label='Train Loss')
ax.plot(val_losses, label='Validation Loss')
utils.plotting.make_fig_pretty(ax, title='Loss vs Epochs', xlabel='Epochs', ylabel='Loss',ctab=True)
plt.show()
# ✅ Check your answer
answer = {
'train_losses': train_losses[-1],
'val_losses': val_losses[-1],
'loss_trend': train_losses[0] > train_losses[-1],
'overfit_check': val_losses[-1] <= val_losses[0] * 1.5 # Should not have increased much
}
checker.check_exercise(4, answer)Overfitting, Underfitting, and Early Stopping
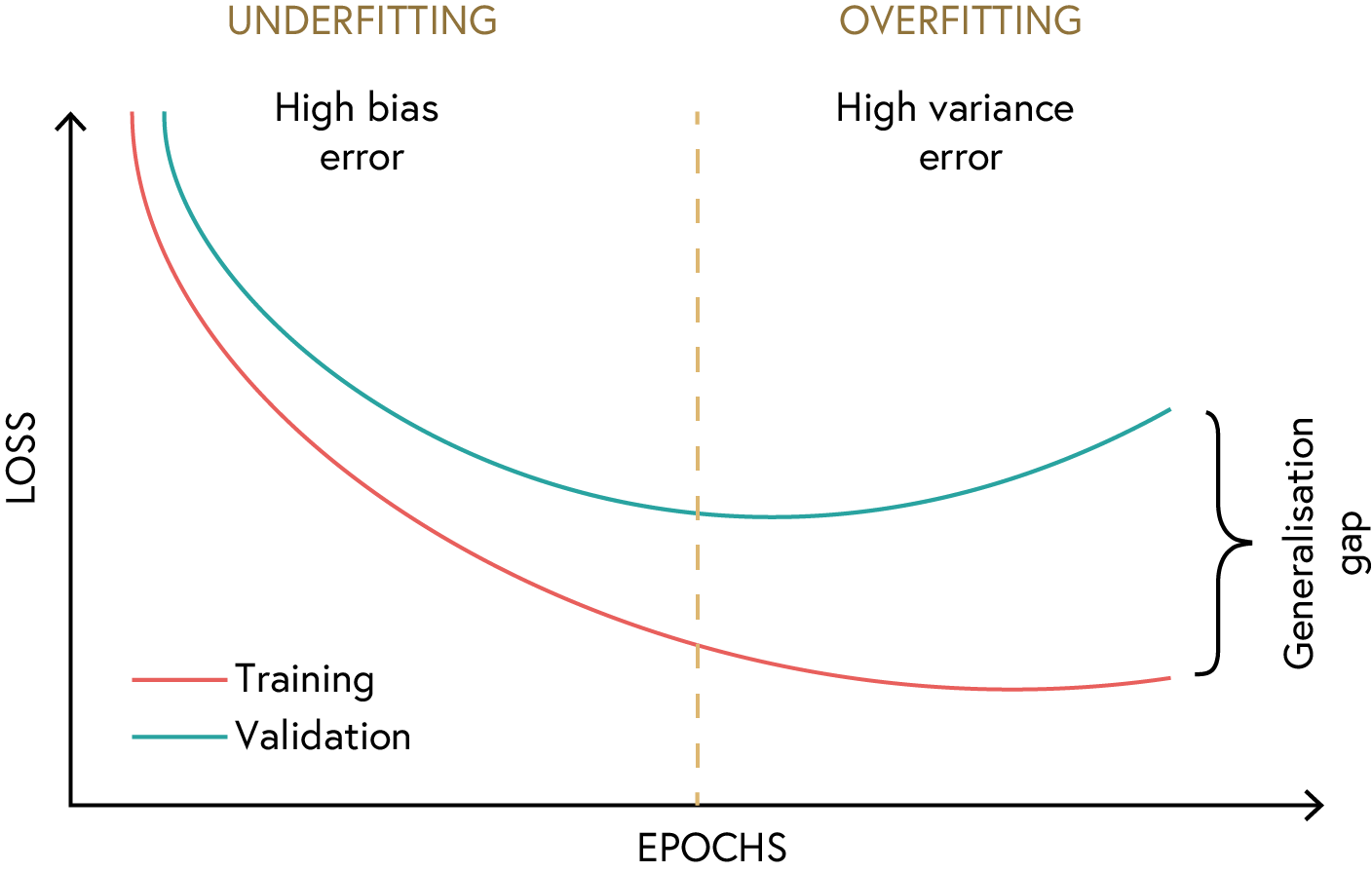
As we can see in the following figure, the training loss decreases over time, while the validation loss follows a similar trend. However, the validation loss starts to slowly deviate from the training loss after a certain number of epochs. This indicates that the model is starting to overfit the training data. The point at which the validation loss starts to increase is known as the “early stopping” point. This is the point at which we should stop training the model to prevent overfitting.
Step 10: Evaluate Model
The next step is to evaluate the model using the validation and test data. The model is evaluated on the validation set during training to monitor its performance and prevent overfitting.
Since we are training a model with MSE loss, we can also plot the predicted output against the actual output to see how well the model is performing. The predicted output should be close to the actual output, and the points should be clustered around the diagonal line. If the points are scattered far from the diagonal line, it indicates that the model is not performing well.
We can also compute the R-squared value to quantify the performance of the model. The R-squared value is a statistical measure that represents the proportion of the variance for a dependent variable that’s explained by an independent variable or variables in a regression model. The R-squared value ranges from 0 to 1, where 0 indicates that the model does not explain any of the variance in the data, and 1 indicates that the model explains all of the variance in the data.
For this step we are going to use the test set to evaluate the model.
# Set model to evaluation mode
model.eval()
# Disable gradient calculation
with torch.no_grad():
# Forward pass through the model
predictions = model(inputs)
# Compute loss
loss = criterion(predictions, targets)
# Exercise 5: Model Evaluation 🎯
# In this exercise, you will:
# 1. Evaluate your trained model on the test set
# 2. Calculate R-squared score to measure model performance
# 3. Visualize actual vs. predicted values for one joint
# Put the model in evaluation mode
model.eval()
# Predict on the test set without computing gradients
with torch.no_grad():
test_predictions = # Your code here
# Calculate the test loss
test_loss = # Your code here
# Convert predictions and targets back to original scale
test_predictions_original = # Your code here
test_targets_original = # Your code here
# Calculate the R-squared score
r2_score = utils.ml.r2_score(test_targets_original, test_predictions_original)
# Print evaluation metrics
print(f"Test Loss: {test_loss.item():.4f}")
print(f"R-squared Score: {r2_score:.4f}")
# Visualize actual vs. predicted values for the shoulder pitch joint (first joint)
fig, axes = plt.subplots(figsize=(16, 20), nrows=5)
for ix, joint in enumerate(y_test.columns):
axes[ix].plot(test_targets_original[:, ix], test_predictions_original[:, ix], 'o', fillstyle='none', markersize=2)
axes[ix].plot(test_targets_original[:, ix], test_targets_original[:, ix], 'r--')
utils.plotting.make_fig_pretty(axes[ix], title=f"{joint}", ylabel='Predicted',
xtick_fsize=10, ytick_fsize=10,
title_fsize=12, xlabel_fsize=10)
if ix == 4:
axes[ix].set_xlabel('ACTUAL')
# ✅ Check your answer
answer = {
'test_loss': test_loss.item(),
'r2_score': r2_score,
'predictions_shape': test_predictions_original.shape,
'values_match': test_predictions_original.shape == test_targets_original.shape
}
checker.check_exercise(5, answer)