
# Download utils from GitHub
!wget -q --show-progress https://raw.githubusercontent.com/CLDiego/uom_fse_dl_workshop/main/colab_utils.txt -O colab_utils.txt
!wget -q --show-progress -x -nH --cut-dirs=3 -i colab_utils.txtfrom pathlib import Path
import sys
repo_path = Path.cwd()
if str(repo_path) not in sys.path:
sys.path.append(str(repo_path))
import utils
import torch
import scipy
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import inspect
print("GPU available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("GPU device:", torch.cuda.get_device_name(0))
else:
print("No GPU available. Please ensure you've enabled GPU in Runtime > Change runtime type")
checker = utils.core.ExerciseChecker("SE03P")1. Introduction to PINNs
Definition: Physics-Informed Neural Networks (PINNs) are neural networks that are trained to solve supervised learning tasks while respecting physical laws described by partial differential equations.
Physics-Informed Neural Networks (PINNs) are a class of deep learning models that integrate physical laws, typically expressed as partial differential equations (PDEs), directly into the learning process. Instead of relying solely on data, PINNs leverage known physics to constrain the model, allowing for more robust learning, especially in scenarios where data is scarce or noisy.
PINNs combine two major concepts:
| Component | Description | Role |
|---|---|---|
| Neural Networks | Deep learning models that can approximate complex functions | Learn patterns from data |
| Physical Laws | Mathematical equations describing system behavior | Enforce physical constraints |
1.1 Why PINNs?
Traditional numerical methods for solving PDEs face several challenges:
| Challenge | Traditional Methods | PINN Solution |
|---|---|---|
| Computational Cost | High for complex geometries | Efficient once trained |
| Mesh Requirements | Need fine meshes | Meshless approach |
| Limited Data | Require complete boundary conditions | Can work with sparse data |
| High Dimensions | Suffer from curse of dimensionality | Better scaling with dimensions |
| Generalisation | Limited to specific problems | Generalises to new conditions |
2. Case Study: Navier-Stokes Equations
These equations govern the motion of incompressible fluids in 2D:
Momentum equations: \(\begin{aligned} \frac{\partial u}{\partial t} + \lambda_1 (u \frac{\partial u}{\partial x} + v \frac{\partial u}{\partial y}) &= -\frac{\partial p}{\partial x} + \lambda_2 (\frac{\partial^2 u}{\partial x^2} + \frac{\partial^2 u}{\partial y^2}) \quad \text{(momentum in x-direction)} \\ \frac{\partial v}{\partial t} + \lambda_1 (u \frac{\partial v}{\partial x} + v \frac{\partial v}{\partial y}) &= -\frac{\partial p}{\partial y} + \lambda_2 (\frac{\partial^2 v}{\partial x^2} + \frac{\partial^2 v}{\partial y^2}) \quad \text{(momentum in y-direction)} \end{aligned}\)
Continuity equation (incompressibility condition): \(\frac{\partial u}{\partial x} + \frac{\partial v}{\partial y} = 0\)
Meaning of terms:
- $u(x, y, t)$: horizontal velocity
- $v(x, y, t)$: vertical velocity
- $p(x, y, t)$: pressure
- $\lambda_1$: convection coefficient (usually 1)
- $\lambda_2 = \nu $: kinematic viscosity
These equations state that:
- Fluids accelerate due to pressure differences and internal friction (viscosity)
- Mass is conserved → the flow remains incompressible
2.1 Flow past a cylinder
In this notebook we are going to explore a realistic scenario of incompressible fluid flow as described by the ubiquitous Navier-Stokes equations. Navier-Stokes equations describe the physics of many phenomena of scientific and engineering. Often, the Navier-Stokes equations are solved using numerical methods, such as finite element or finite volume methods. However, these methods can be computationally expensive and time-consuming, especially for complex geometries and boundary conditions. In this workshop, we will use a dataset of incompressible fluid flow around a cylinder. The dataset is generated using a finite volume method and contains the velocity and pressure fields of the fluid flow. The dataset consists of the following variables:
| Variable | Description |
|---|---|
| u | x-component of velocity |
| v | y-component of velocity |
| p | pressure |
| t | time |
The dataset was prepared using the following simulation parameters:
- Domain: ( [-15, 25] \times [-8, 8] )
- Reynolds number: ( Re = 100 )
- Numerical method: Spectral/hp-element solver (NekTar)
- Mesh: 412 triangular elements, 10th-order basis functions
- Integration: Third-order stiff scheme until steady vortex shedding
For this problem, we want to predict the Convective term $\lambda_1$, the viscous term $\lambda_2$, as well as a reconstruction of the pressure field $p$.
data_path = Path(Path.cwd(), 'datasets')
dataset_path = utils.data.download_dataset('cylinder',
dest_path=data_path,
extract=False,
remove_compressed=False)data = scipy.io.loadmat(dataset_path)
u_star = data['U_star'] # velocity n x 2 x time
p_star = data['p_star'] # pressure n x time
x_star = data['X_star'] # coordinates n x 2
time = data['t'] # time n x 1
print(f'We have {u_star.shape[0]} points in space, {u_star.shape[1]} dimensions and {u_star.shape[2]} time steps.')utils.plotting.wake_cylinder_interactive(x_star, u_star, p_star, time, figsize=(12, 6))3. Preparing the dataset
As you can see in the image above, the simulation has been cropped to a smaller domain that does not include the cylinder. Thus, with this dataset we are only using 1% of the total data for training. This is to highlight the ability of PINNs to learn from limited data. In practice, you would typically use a larger portion of the dataset for training. Thus, we are not going to split the dataset into training, validation, and test sets. Instead, we will use the entire dataset for training and testing. This is a common practice in PINNs, where the model is trained on a small portion of the data and then tested on the entire dataset.
The training data consists of the following parameters:
- Region: Small rectangle downstream of cylinder
- Sampled: ( u(x, y, t), v(x, y, t) )
- Size: 5,000 points (~1% of simulation)
- No pressure data used
To prepare the data we need to load the dataset and extract the relevant variables. Furthermore, we need to reshape the data to be compatible with the PINN model.
3.1 Normalisation
For PINNs, the features cannot be normalised in the same way as in traditional machine learning. Standard normalization in PINNs is tricky because physical equations must remain consistent with the scaled variables. The normalisation should be applied to the loss function considering the physics of the problem. This is a more complex process and requires a deeper understanding of the physical equations involved.
In this workshop, we will not cover this topic in detail, but it is important to keep in mind that normalisation in PINNs is not as straightforward as in traditional machine learning.
# Exercise 6: Prepare the data for training 🎯
# Implement:
# 1. Create a meshgrid-like structure for the x, y, and t coordinates
# 2. Flatten the velocity and pressure data into NT x 1 arrays
# 3. Randomly sample N points from the flattened data
# 4. Convert the sampled data into PyTorch tensors
N, T = x_star.shape[0], time.shape[0] # number of points in space and time
# Create coordinate grids
x_flat = x_star[:, 0] # Extract x coordinates
y_flat = x_star[:, 1] # Extract y coordinates
t_flat = time.flatten() # Flatten time array
# Create meshgrid-like structures for visualization
x_coords = # Your code here
y_coords = # Your code here
time_coords = # Your code here
# Extract velocity and pressure data
u_vals = # Your code here
v_vals = # Your code here
p_vals = # Your code here
# Flatten into NT x 1 arrays
x = # Your code here
y = # Your code here
t = # Your code here
u = # Your code here
v = # Your code here
p = # Your code here
idx = # Your code here
x_train = x[idx, :]
y_train = y[idx, :]
t_train = t[idx, :]
u_train = u[idx, :]
v_train = v[idx, :]
# Preparing the data as tensors
x_train = # Your code here
y_train = # Your code here
t_train = # Your code here
u_train = # Your code here
v_train = # Your code here
# ✅ Check your answer
answer = {
'x_train': x_train,
'y_train': y_train,
't_train': t_train,
'u_train': u_train,
'v_train': v_train,
'data_shape': x_train.shape[0]
}
checker.check_exercise(6, answer)4. PINN Architecture
In this workshop we are going to use a Physics-Informed Neural Network (PINN) to solve the Navier-Stokes equations. The PINN model is a neural network that is trained to satisfy the Navier-Stokes equations, as well as the boundary conditions of the problem. The PINN model consists of the following components:
| Component | Purpose | Implementation |
|---|---|---|
| Input Layer | Takes spatial/temporal coordinates | $(x, y, t)$ coordinates |
| Hidden Layers | Learn the underlying patterns | Multiple fully connected layers |
| Output Layer | Predicts physical quantities | Velocity and pressure fields |
| Physics Loss | Enforces PDE constraints | Automatic differentiation |
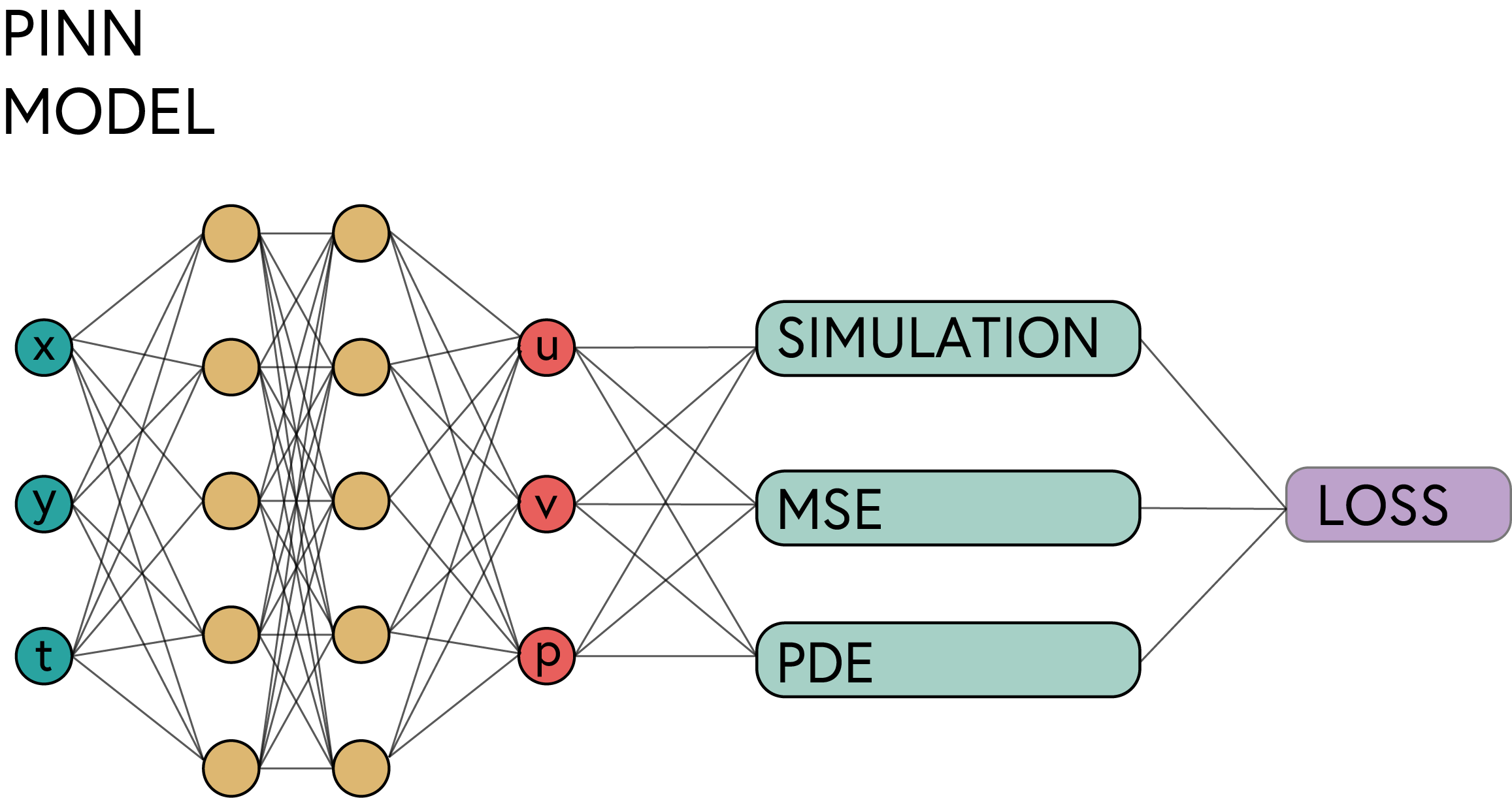
For the connected layers we are going to use the following activation functions:
| Layer | Activation Function |
|---|---|
| Input Layer | Tanh |
| Hidden Layers | Tanh |
| Output Layer | Tanh |
The choice of activation function for the output layer is important, as it can affect the range of the output values. In this case, we are using Tanh to ensure that the output values are in the range [-1, 1]. This is important for the PINN model, as we want to ensure that the predicted values are in the same range as the input features.
# Exercise 7: Model Creation with Weight Initialization 🎯
# Implement:
# 1. Define a class for the Navier-Stokes PINN model
# 2. Initialize the model with a specified number of hidden layers and neurons
# 3. Use Xavier initialization for the weights and biases of each layer
# 4. Define the forward pass to compute the velocity and pressure outputs
# 5. Split the output into u, v, and p components
class NavierStokesPINN(torch.nn.Module):
def __init__(self, hidden_size=20, num_layers=9):
super().__init__()
self.nu = 0.01 # kinematic viscosity
# Neural network architecture
layers = []
# Input layer: x, y, t
input_layer = # Your code here
# Your code here :Initialize weights and biases
layers.append(input_layer)
# Hidden layers
for _ in range(num_layers - 1):
hidden_layer = # Your code here
# Your code here :Initialize weights and biases
layers.append(hidden_layer)
# Output layer: u,v,p because we are enforcing the continuity equation
output_layer = # Your code here
# Your code here :Initialize weights and biases
layers.append(output_layer)
self.net = torch.nn.Sequential(*layers)
def forward(self, x, y, t):
# Combine inputs
xyz = # Your code here
# Forward pass through network
for i in range(len(self.net)-1):
xyz = # Your code here
# Final layer without activation
output = # Your code here
# Split output into u, v, p
u = # Your code here
v = # Your code here
p = # Your code here
return u, v, p
model = NavierStokesPINN(hidden_size=20, num_layers=9)
# ✅ Check your answer
answer = {
'model': model,
'hidden_size': model.net[0].out_features,
'input_size': model.net[0].in_features,
'output_size': model.net[-1].out_features,
'num_layers': len(model.net)
}
checker.check_exercise(7, answer)5. PINN Loss Function
When working with PINNs, the loss function is a crucial component that combines data loss and physics loss. The data loss measures how well the model fits the training data, while the physics loss measures how well the model satisfies the physical constraints defined by the PDEs. Thus, the loss function is defined as follows:
\[\text{Loss} = \text{Data Loss} + \text{Physics Loss}\] \[\text{Data Loss} = \frac{1}{N} \sum_{i=1}^{N} (u_i - u_{\text{pred}, i})^2 + (v_i - v_{\text{pred}, i})^2\] \[\text{Physics Loss} = \frac{1}{M} \sum_{j=1}^{M} (f_{u,j}^2 + f_{v,j}^2 + f_{c,j}^2)\]Where:
- $f_u = \frac{\partial u}{\partial t} + u \frac{\partial u}{\partial x} + v \frac{\partial u}{\partial y} + \frac{\partial p}{\partial x} - \nu \left( \frac{\partial^2 u}{\partial x^2} + \frac{\partial^2 u}{\partial y^2} \right)$
- $f_v = \frac{\partial v}{\partial t} + u \frac{\partial v}{\partial x} + v \frac{\partial v}{\partial y} + \frac{\partial p}{\partial y} - \nu \left( \frac{\partial^2 v}{\partial x^2} + \frac{\partial^2 v}{\partial y^2} \right)$
- $f_c = \frac{\partial u}{\partial x} + \frac{\partial v}{\partial y}$
- $f_c$: Continuity equation (incompressibility condition)
- $f_u$: Momentum equation in x-direction
- $f_v$: Momentum equation in y-direction
- $N$: Number of data points in the training set
- $M$: Number of points in the physics loss (collocation points)
The physics loss ensures that the solution satisfies the Navier-Stokes equations, while the data loss ensures the solution matches known data points. This dual optimization approach is what makes PINNs powerful for solving PDEs.
5.1 Automatic Differentiation in PINNs
One of the key features of PINNs is their ability to automatically compute derivatives using automatic differentiation (autograd). This is crucial for enforcing physical constraints defined by PDEs.
5.1.1 How Automatic Differentiation Works
When we use torch.autograd.grad(), PyTorch computes derivatives through the computational graph:
Snippet 1: Basic usage of
torch.autograd.grad()
u_t = torch.autograd.grad(u, t, grad_outputs=torch.ones_like(u), create_graph=True)[0]
The torch.autograd.grad() function returns a tuple of gradients. The first element is the gradient of u with respect to t.
| Parameter | Purpose | Description |
|---|---|---|
u |
Target tensor | The output we want to differentiate |
t |
Source tensor | The variable we’re differentiating with respect to |
grad_outputs |
Scaling factor | Usually ones, for direct gradient computation |
create_graph |
Enable higher derivatives | Needed for second derivatives |
# Exercise 8: Compute Residuals 🎯
# Implement:
# 1. Define a function to compute the residuals of the Navier-Stokes equations
# 2. Enable gradients for the input variables (x, y, t)
# 3. Compute the first and second derivatives of the velocity and pressure fields
# 4. Calculate the residuals for the u and v momentum equations and the continuity equation
# 5. Return the residuals as outputs
def compute_ns_residuals(model, x, y, t):
# Your code here: Enable gradients
# Get predictions
u, v, p = model(x, y, t)
# First derivatives
u_t = # Your code here
u_x = # Your code here
u_y = # Your code here
v_t = # Your code here
v_x = # Your code here
v_y = # Your code here
p_x = # Your code here
p_y = # Your code here
# Second derivatives
u_xx = # Your code here
u_yy = # Your code here
v_xx = # Your code here
v_yy = # Your code here
# Compute residuals
f_u = # Your code here
f_v = # Your code here
f_c = # Your code here
return f_u, f_v, f_c# Create a small test case to verify the residual calculation
test_x = torch.ones((5, 1), requires_grad=True)
test_y = torch.ones((5, 1), requires_grad=True)
test_t = torch.ones((5, 1), requires_grad=True)
test_fu, test_fv, test_fc = compute_ns_residuals(model, test_x, test_y, test_t)
# ✅ Check your answer
answer = {
'f_u_shape': test_fu.shape,
'f_v_shape': test_fv.shape,
'f_c_shape': test_fc.shape,
'has_gradients': test_fu.requires_grad
}
checker.check_exercise(8, answer)6. PINN Optimiser and training
When training a PINN model, the choice of optimiser is crucial for achieving good performance. A common practice is to use a two-step approach:
- Use a standard optimiser (like Adam) to train the model, often called the “warm-up” phase.
- Switch to a more advanced optimiser (like L-BFGS) for fine-tuning.
This approach allows for faster convergence in the initial phase and better performance in the final phase.
Note: The use of only Adam or L-BFGS is also possible, however, without the fine-tuning step the model will have an issue finding the right scale of the loss function. Resulting in a model that creates good qualitative results, but poor quantitative results.
The warm-up phase follows the standard training process, where the model is trained using a standard optimiser (like Adam) for a certain number of epochs. The fine-tuning phase uses a more advanced optimiser (like L-BFGS) to refine the model parameters and improve performance.
To use the L-BFGS optimiser, we need to define a closure function that computes the loss and gradients. The closure function is called by the optimiser to compute the loss and gradients, and it should return the loss value. The closure function should also zero out the gradients before computing the loss, as shown in the code snippet below.
import torch.optim as optim
# Define the model
model = PINNModel()
# Define the loss function
loss_function = PINNLoss()
# Define the optimizer
optimizer = optim.LBFGS(model.parameters(),
lr=0.1,
max_iter=500,
max_eval=500,
tolerance_grad=1e-8,
tolerance_change=1e-8,
history_size=50,
line_search_fn="strong_wolfe")
# Define the closure function
def closure():
optimizer.zero_grad()
loss = loss_function(model)
loss.backward()
return loss
# Training loop
for epoch in range(num_epochs):
optimizer.step(closure)
# Exercise 9: The training loop 🎯
# Implement:
# 1. Define a training function for the PINN model
# 2. Use Adam optimizer for the first phase of training
# 3. Use L-BFGS optimizer for the second phase of training
# 4. Compute the loss as a combination of data loss and physics loss
# 5. Use a closure function to compute the loss and gradients for L-BFGS
def train_pinn(model, data, epochs=10000, use_lbfgs=True):
count = 0
bLBFGS = False
x, y, t, u_true, v_true = data
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = # Your code here: move model to device
# Move data to device
x = # Your code here
y = # Your code here
t = # Your code here
u_true = # Your code here
v_true = # Your code here
# Adam optimization first
optimizer = # Your code here
mse_loss = # Your code here
losses = {
'data_loss': [],
'physics_loss': [],
'total_loss': [],
'lbfgs_data_loss': [],
'lbfgs_physics_loss': [],
'lbfgs_total_loss': []
}
def closure():
nonlocal count
optimizer.zero_grad()
# Data loss
u_pred, v_pred, _ = # Your code here
data_loss = # Your code here
# Physics loss
f_u, f_v, f_c = # Your code here
physics_loss = # Your code here
# Total loss
loss = # Your code here
# Backpropagation
# Your code here: compute gradients
# Store losses
if bLBFGS:
losses['lbfgs_data_loss'].append(data_loss.item())
losses['lbfgs_physics_loss'].append(physics_loss.item())
losses['lbfgs_total_loss'].append(loss.item())
print('\r' + f"Training with LBFGS at epoch {count}: data Loss: {data_loss.item()}, "
f"physics Loss: {physics_loss.item()}, "
f"total Loss: {loss.item()}", end='')
count += 1
else:
losses['data_loss'].append(data_loss.item())
losses['physics_loss'].append(physics_loss.item())
losses['total_loss'].append(loss.item())
return loss
# Train with Adam
pbar = tqdm(range(epochs), desc="Training with Adam")
for _ in pbar:
# Your code here: compute loss
loss =
# Your code here: compute gradients
pbar.set_postfix({
'data_loss': losses['data_loss'][-1],
'physics_loss': losses['physics_loss'][-1],
'total_loss': losses['total_loss'][-1]
})
# L-BFGS optimization
if use_lbfgs:
bLBFGS = True
optimizer = # Your code here: configure L-BFGS optimizer
optimizer.step(closure)
return model, losses
# Test with a smaller number of epochs
test_model = NavierStokesPINN(hidden_size=20, num_layers=9)
data_tuple = (x_train[:10], y_train[:10], t_train[:10], u_train[:10], v_train[:10])
test_trained_model, losses = train_pinn(test_model,
data_tuple,
epochs=2,
use_lbfgs=False)# ✅ Check your answer
# Analyze the training function to extract important components
train_fn_code = inspect.getsource(train_pinn)
# Check for key components in the code
has_adam = 'Adam' in train_fn_code
has_lbfgs = 'LBFGS' in train_fn_code
has_closure = 'def closure' in train_fn_code
has_data_loss = 'data_loss' in train_fn_code
has_physics_loss = 'physics_loss' in train_fn_code
computes_residuals = 'compute_ns_residuals' in train_fn_code
updates_weights = 'optimizer.step()' in train_fn_code
backprop = 'backward()' in train_fn_code
answer = {
'function_code': train_fn_code, # For deeper inspection
'has_adam': has_adam,
'has_lbfgs': has_lbfgs,
'uses_closure': has_closure,
'has_data_loss': has_data_loss,
'has_physics_loss': has_physics_loss,
'computes_residuals': computes_residuals,
'updates_weights': updates_weights,
'uses_backpropagation': backprop,
'learning_rate': 0.001 if 'lr=0.001' in train_fn_code else None,
'optimizer_params': {
'has_max_iter': 'max_iter=' in train_fn_code,
'has_line_search': 'line_search_fn=' in train_fn_code
}
}
checker.check_exercise(9, answer)# Run the training loop with the full dataset
# Initialize model
model = NavierStokesPINN(hidden_size=20, num_layers=9)
# Train model
trained_model, losses = train_pinn(
model,
(x_train, y_train, t_train, u_train, v_train),
epochs=10000,
use_lbfgs=True
)
# save the model
torch.save(trained_model.state_dict(), 'se03_pinn_model.pth')# Visualize the loss history
def plot_loss_history(losses):
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(losses['data_loss'], label='Data Loss',)
ax.plot(losses['physics_loss'], label='Physics Loss')
ax.plot(losses['total_loss'], label='Total Loss')
ax.plot(losses['lbfgs_data_loss'], label='LBFGS Data Loss')
ax.plot(losses['lbfgs_physics_loss'], label='LBFGS Physics Loss')
ax.plot(losses['lbfgs_total_loss'], label='LBFGS Total Loss')
ax.set_yscale('log')
utils.plotting.make_fig_pretty(ax, title='Loss History', xlabel='Epochs', ylabel='Loss')
plot_loss_history(losses)6.1 Evaluation
Unlike standard models where performance is often quantified with scalar metrics like Mean Squared Error (MSE) or R-squared, PINNs are typically evaluated by comparing predicted and true physical fields over time (e.g., velocity and pressure fields in fluid dynamics).
Here, we generate predictions from the trained model across all time steps and compare them to the ground truth values. Since we’re modeling time-dependent flow behavior, we loop over each time snapshot and feed spatial coordinates (x, y) along with the corresponding time value t into the model. We compute and collect the predicted fields:
-
u_pred: Predicted horizontal velocity -
v_pred: Predicted vertical velocity -
p_pred: Predicted pressure
These are then compared against the ground truth data from the test set for visual inspection and potential error metrics like relative L2 norm or RMSE (if applicable).
requires_grad=True. This is important for the autograd engine to track operations on these tensors and compute gradients correctly. This is especially crucial when using optimisers like L-BFGS, which rely on gradient information to update model parameters.
# Exercise 10: Inference and Visualization 🎯
# Implement:
# 1. Load the trained model
# 2. Set the model to evaluation mode
# 3. Move the model to CPU for inference
# 4. Create input tensors with requires_grad=True
# 5. Get predictions for u, v, and p
# 6. Store predictions in lists and convert to arrays
# 7. Reshape ground truth data
model = NavierStokesPINN(hidden_size=20, num_layers=9)
model.load_state_dict(torch.load('se03_pinn_model.pth'))
model.eval()
model.to('cpu')
with torch.no_grad():
u_pred = []
v_pred = []
p_pred = []
for t_idx in range(time.shape[0]):
# Create input tensors with requires_grad=True
x_tensor = # Your code here
y_tensor = # Your code here
t_tensor = # Your code here
# Get predictions - temporarily enable gradients
with torch.enable_grad():
u_t, v_t, p_t = # Your code here
# Store predictions
u_pred.append(u_t.detach().cpu().numpy())
v_pred.append(v_t.detach().cpu().numpy())
p_pred.append(p_t.detach().cpu().numpy())
# Convert to arrays and reshape
u_pred = # Your code here
v_pred = # Your code here
p_pred = # Your code here# Reshape ground truth data
u_true = u_star[:, 0, :] # Shape: (N, T)
v_true = u_star[:, 1, :] # Shape: (N, T)
p_true = p_star # Shape: (N, T)
# ✅ Check your answer
answer = {
'u_pred_shape': u_pred.shape,
'v_pred_shape': v_pred.shape,
'p_pred_shape': p_pred.shape,
'requires_grad_used': True
}
checker.check_exercise(10, answer)
# Create visualization
utils.plotting.visualize_flow_comparison_interactive(
x_star, u_true, v_true, p_true,
u_pred, v_pred, p_pred, time,
figsize=(18, 4),
)